
Geographic Concentration
Description
Definition: Geographic concentration analysis compares high or low concentrations of multiple variables to understand how location impacts client conditions. It often uses location quotients (LQs) to quantify concentrations.
Purpose: Highlights areas where services could be ramped up to better meet client need, and pinpoints "hotspots" or regions with specific emerging needs or resources.
Examples:
- Identifying neighborhoods with higher-than-expected concentrations of eviction cases.
- Comparing service levels with poverty concentrations across regions.
Key Insight: Concentration analysis reveals the interplay between variables and locations, helping you understand how geographic factors influence service needs or outcomes.
Example Data Question
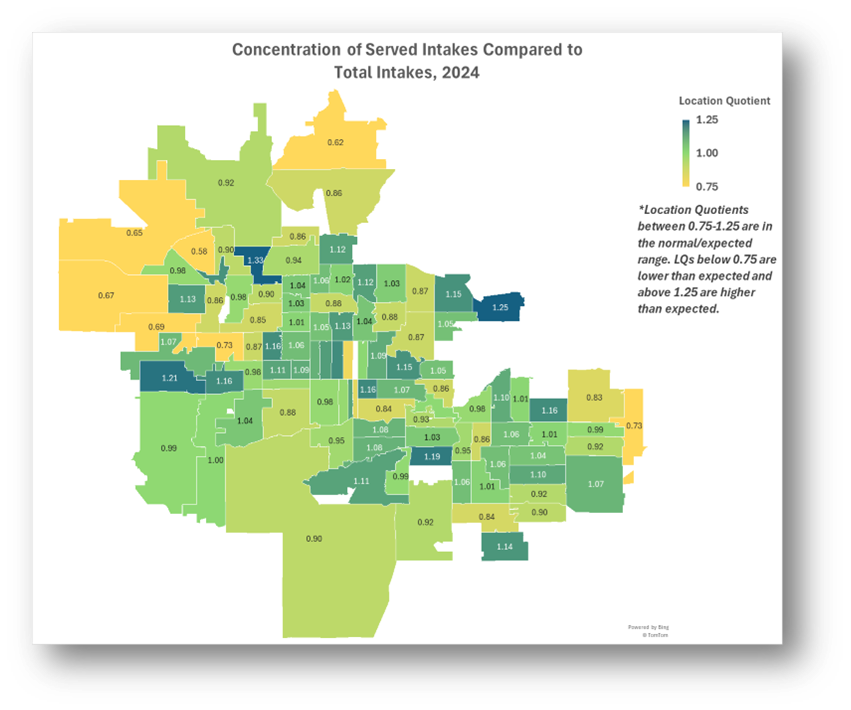
How did the proportion of people from different zip codes to whom we provided service compare to the proportion of people who requested assistance last year (e.g. Are there any zip codes in our service area from which we are serving disproportionately more or fewer cases than we expect based on intake volume?)
Recreate This Analysis
Data Sources
Intake data from your case management system:
- Fields:
- Demographics about which you are curious, such as Age at Intake, Gender, Race, Ethnicity, With Disabilities, Veteran, Percentage of Poverty, Number in Household, Citizenship Status, Language, Living Arrangement, County, State, Zip Code, etc.
- Dates: Date of Earliest, Intake Date, Prescreen Date, Open Date, Close Date, Date of Rejection, and Date of Birth (for use in an age-related formula).
- Case Information: Legal Problem Code, Problem Code Categories, Close Reason, Rejection Reason, Disposition, Intake Type, etc.
- Filters/Report Structure:
- Date Filters: Intake Date in the last year.
- Exclude/Filter Out: Test or fake cases and clients and duplicate cases using whichever fields your organizations uses to identify these cases and clients, such as Rejection Reason, Client Name, Case Status, Funding Code, etc.
- Include: Cases that were closed with service, rejected without service, and remain open.
- One Row/Record Per Case: Ensure that downloaded data includes just one record (one row) per case. If necessary, text join fields that cause more than one row/record per case.
- Export Format:
If downloading from LegalServer, it is recommended that report results are exported as CSV files (an option that may be set up under Additional Display Format – remember to check Headers in First Row) and saved as Excel files to avoid formatting issues, particularly related to date fields.
Example Analyses Steps
- Download data from your case management system (CMS), use an API link to connect to data in your CMS, or connect to your CMS data directly via an ODBC connection or other method.
- Make sure to include intakes that remain open, that were rejected, and that were closed (either in the year they were opened or later).
- Create Map
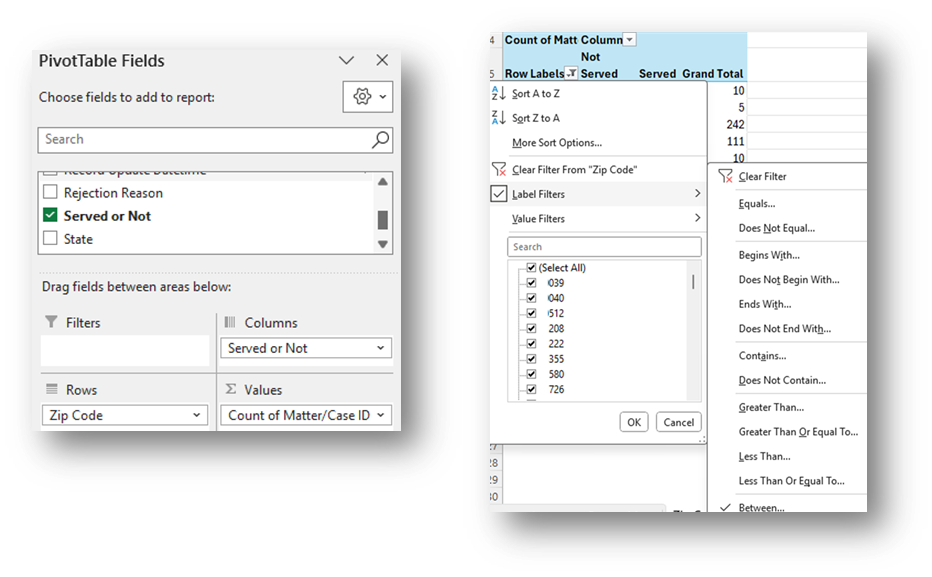
- Click Insert along the top ribbon, then click on PivotTable.
- Place the PivotTable in a New Worksheet and rename it Map.
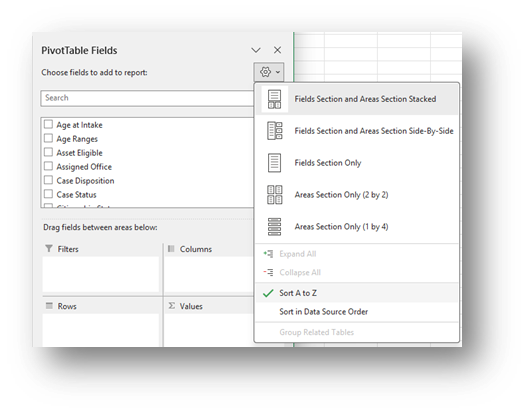
Sort the fields in the PivotTable Fields window, by clicking on the Gear Icon, and selecting Sort A to Z.
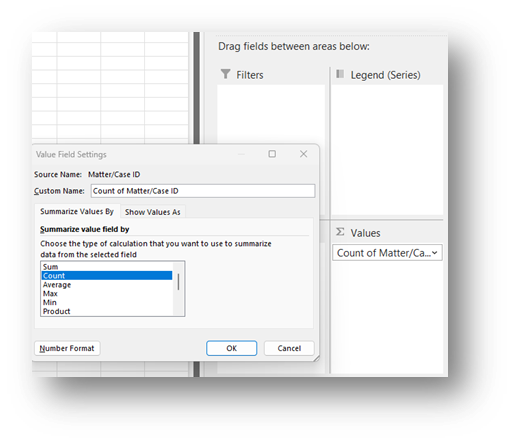
- Add the Matter/Case ID (or Case Number) field to the Values window and make sure the calculation is Count.
If you see Sum of Matter/Case ID, click on the drop down, select Value Field Settings, and change the calculation type to Count.
- Drag the Zip Code field in the Rows window. Click on the drop-down in the Row Labels cell of the PivotTable, click on Label Filters, select Between, and enter the range of Zip Codes in your service area in the Label Filter window that pops up (specific zip code numbers are distorted in this visual to protect confidential information).
Drag the Served or Not formula into the Columns Window.
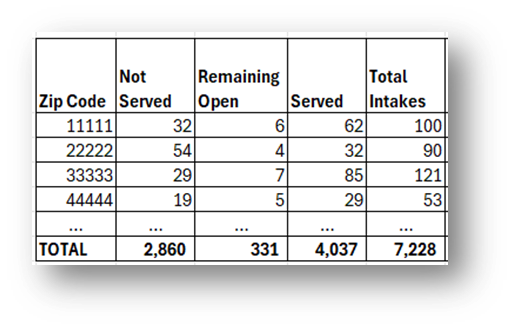
Copy PivotTable data (values only) into a calculation table to the right of the data, change “Row Labels” to “Zip Code”.
- Click Insert along the top ribbon, then click on PivotTable.
- Perform Calculations:
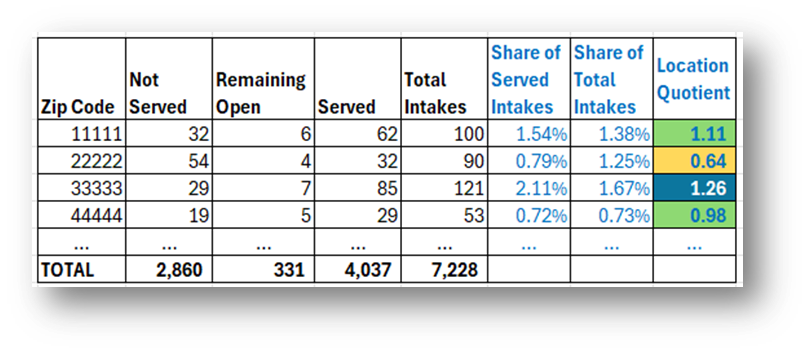
- Add columns to calculate each Zip Code’s Share of Served Intakes and Share of Total Intakes by dividing each county's numbers by the total column numbers.
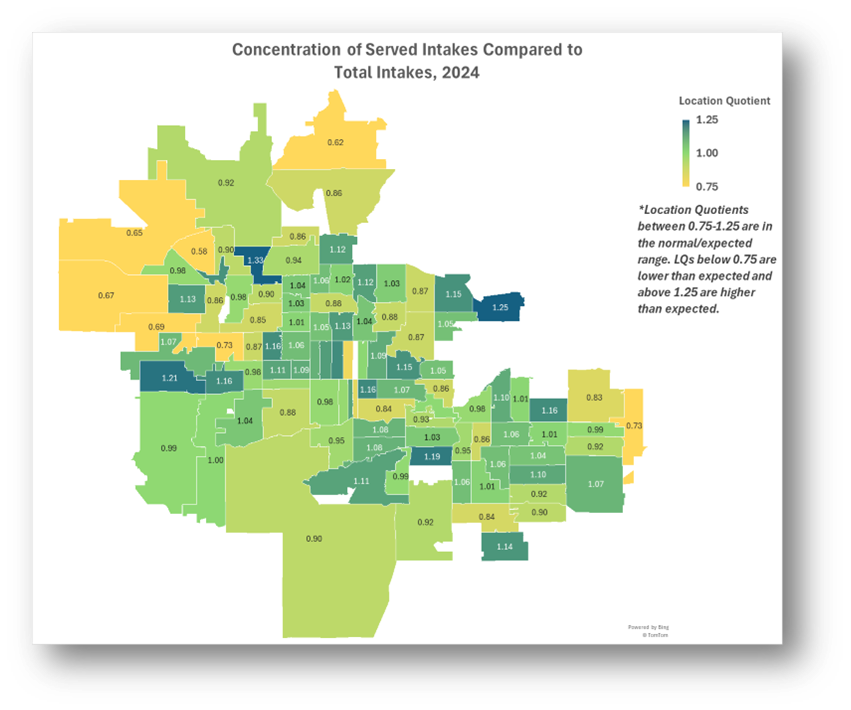
- Calculate each county’s Location Quotient (LQ) by dividing the Share of Served Intakes and Share of Total Intakes.
Note that LQs in the range of 0.75-1.25 are generally considered in the normal/expected range. LQs below 0.75 are lower than expected and above 1.25 are higher than expected.
- Create map:
- Highlight the Zip Code column and the Location Quotient column in your calculation table and click on Insert-Maps-Filled Maps from the top ribbon.
- Change the Map’s title by simply clicking on “Chart Title” and typing your preferred title.
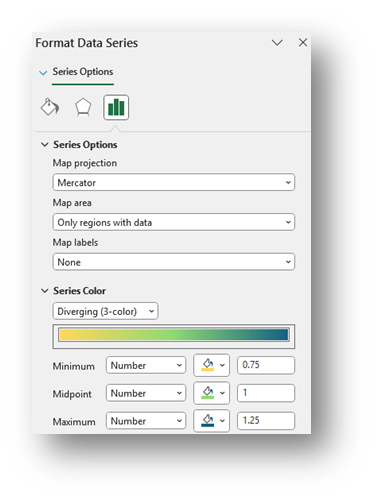
- Right-click on a shaded zip code in the map and select Format Data Series.
- Select Map projection (usually Automatic or Mercator) and consider changing Map area to Only regions with data. Leave Map labels set to None.
Change the Series Color to Diverging (3-color) & Change the Minimum, Midpoint, and Maximum to Numbers and enter 0.75, 1, and 1.25. You may change any of the colors. Select colors that indicate less service than expected for numbers close to the Minimum, expected service for numbers close to the Midpoint, and more service than expected for numbers close to the Maximum.
- To add labels, click the green plus sign in the top right corner of the map and selecting Data Labels in the Chart Elements box. To edit the Data Labels, select More Data Label Options to be taken to the Format Data Labels window.
Check Category Name and Value and change the Number formatting if needed (zip code labels (Category Name) are not added to this visual to protect confidential information).
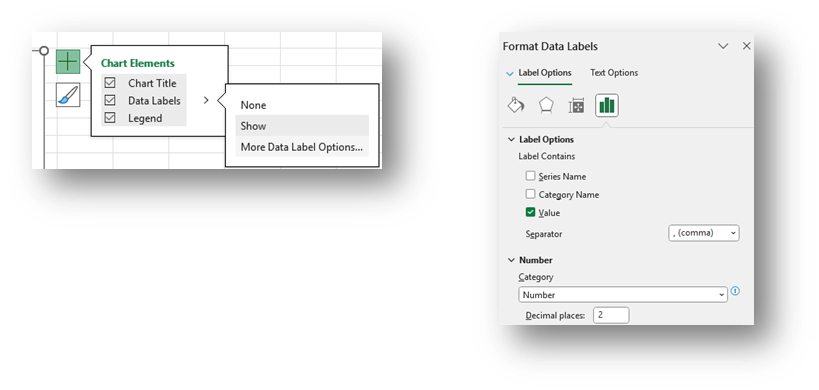
- Highlight any data label or the Legend on the map and change the font from the font options across the top of the Home screen.
- Add a note explaining whether the LQs outside of or within the normal/expected range.
Related Questions You May Ask
- Does the geographic concentration of intakes match that of served people, including those with specific demographics, groups, or legal problems?
- How does the geographic concentration of served people compare to people rejected?
- Identifying concentration allows you to move beyond questions of “high/low” to questions of “more than expected or less than expected”.
- The location quotient is a commonly used measure of concentration, and it can yield important insights into the data.
- Are there communities in your service area generating fewer than expected served cases (LQ <1)? Why might that be?
- Are there communities in your service area generating more than expected served cases (LQ>1)? Do you know why?
- Are levels of concentration throughout your service area (the distribution of LQs on a map) the result of a conscious effort on the part of your organization, or is it simply determined by the population seeking your services?